Making this Astro site more Agent-Friendly
For the last few months I’ve been tinkering with improving this site for AI agent consumers and after reading Dachary Carey’s article on Astro’s removal of llms.txt I went down a bit of a rabbit hole, finding Joost de Valk’s “agent-ready” piece along the way. Here’s the result of that little side-quest.
Existing “agent friendly” features
This site has always had stuff to help machines understand its content: it has sane, predictable URLs, seo-friendly meta tags and <link rel="canonical">. A sitemap is generated by @astrojs/sitemap and the three RSS feeds are advertised on every page. The markup is semantic and includes an appropriate sprinkling of microformats and schema.org stuff. All pages have sensible OG data and auto-generated OG images. I also publish machine-readable records over AT Protocol. Some of this is legit helpful for AI User Agents but over the last year I’ve also added stuff specifically for them…
Markdown versions of my content
Every article and note has a static .md version so appending .md to any URL will return a markdown version of the page (try it for this article). I also include “copy / open as Markdown” buttons at the end of every post, though that’s mainly for humans copypasta’ing into chat interfaces.
An llms.txt index
I generate an llms.txt at build time which includes:
- A brief intro about me and this website.
- Links to important external identities (socials etc).
- What I’m doing now, pulled from my now page.
- A list of all the articles and notes as markdown links.
- A list of other pages, including the styleguide.
You can see it live here.
JSON-LD
I include a full JSON-LD @graph of structured data in every page which includes Person, Organization and WebSite, plus BlogPosting for content pages.
<script type="application/ld+json"> { "@context": "https://schema.org", "@graph": [ { "@type": "Person", "@id": "https://danny.is/#person" }, { "@type": "WebSite", "@id": "https://danny.is/#website" }, { "@type": "BlogPosting", "headline": "…", "datePublished": "…" } ] }</script>Auditing for Agent Friendliness
Dachary Carey’s afdocs tool checks against the spec at agentdocsspec.com, which is primarily designed to ensure content is agent-readable and navigable. Cloudflare’s isitagentready.com is more focussed on conformity with emerging agent discovery standards. Running bunx afdocs check http://danny.is --verbose yielded these warnings & failures, while isitagentready.com gave me a pretty shit score and recommended a bunch of potential improvements.
As with most automated audit tools, these are blunt instruments with very little context about this website. So the goal here isn’t improving scores, it’s using the data to actually improve the site.
Better Agent-Friendliness
Here’s what I actually did off the back of these two audits:
1. Update robots.txt
I updated my robots.txt to use the Content Signals convention:
User-Agent: *Content-Signal: search=yes, ai-input=yes, ai-train=noAllow: /This is a preference signal, so the AI firms will probably ignore it.
2. Have every page point at llms.txt
My llms.txt exists purely to tell AI agents how to get what they need from this site, so it’s super important that they can actually find it. The HTML for an article looks something like this:
<head> ...</head><body> <main> <article class="h-entry" itemscope itemtype="https://schema.org/Article" > ... </article> </main></body>Which means any agent using a WebFetch tool that returns markdown is unlikely to see anything outside of <main>. If we want every fetch to include a pointer to llms.txt, it’s not enough to have a link in our <head>.
I now insert a LLMDiscoveryNote.astro component immediately after the opening <main> on every page. It’s pretty simple:
<p class="sr-only"> For AI agents and crawlers: a structured index of this site is available at <a href="https://danny.is/llms.txt">https://danny.is/llms.txt</a>.</p>We should do the same for our markdown versions. Let’s add this to the top of them all:
> For the complete site index, see [llms.txt](https://danny.is/llms.txt)3. Serve markdown to UAs asking for it
Since user agents can send an Accept header with their requests and we already have markdown versions of our content, we should probably serve markdown to anyone requesting plain ol’ /writing/<slug> URLs with an Accept: text/markdown header. We can do this for both notes and articles with a little addition to our vercel config:
{ "src": "^/writing/([^/]+)/?$", "has": [{ "type": "header", "key": "accept", "value": ".*text/markdown.*" }], "dest": "/writing/$1.md", "headers": { "content-type": "text/markdown; charset=utf-8" }}Browsers never send Accept: text/markdown so they’re unaffected by this, but we need to make sure “negotiable URLs” like this carry Vary: Accept so CDNs don’t accidentally serve markdown when they shouldn’t.
While we’re here, we can also respond to Accept: text/markdown requests to the root of danny.is with the contents of our llms.txt rather than our homepage HTML.
4. Advertise the index Even More
Since llms.txt is so important, let’s also add a Link header to every response and a <link> tag to every HTML document:
Link: </llms.txt>; rel="describedby"<link rel="describedby" type="text/markdown" href="/llms.txt">5. Make it easier to discover markdown versions
Our llms.txt currently includes a big old list of markdown links to all our content, but the URLs point at the HTML versions. It makes much more sense to use the .md URLs in this context. So now the links in llms.txt point to markdown versions if they exist.
While we’re here, we should make sure content pages include a <link rel="alternate" type="text/markdown" href="<markdown version>.md">.
6. Turn meta-refresh redirects into propa HTTP redirects
I use redirects in two places on this site:
- Those hard-coded in
redirects.tswhich forward URLs like https://danny.is/meeting to external services. - Articles with a
redirectURLfrontmatter property which forward to content hosted elsewhere.
I use Astro redirects for the former and meta-refresh for the latter, though since this is a statically generated site they all end up as HTML meta-refresh pages in the generated /dist.
We can improve on this by having our astro build also generate a host-agnostic dist/redirects.json containing all of these, in this kinda form:
{ "version": 1, "redirects": [{ "source": "/meeting", "destination": "https://cal.com/dannysmith", "status": 302 }]}Then as part of our Vercel-specific deployment action we can use this to generate an appropriate Build Output API config which returns proper 302 redirects for these routes. The meta-refresh pages stay in the static build for the sake of portability, as does dist/redirects.json which is the source of truth about how server-side redirects should work.
So where did we end up?
These little tweaks ended up making quite a difference to our audit metrics.
→ bunx afdocs check https://danny.is --verbose...16 passed, 3 warnings, 3 failed, 1 skipped (23 total)The remaining warnings & failures are all false positives as far as I’m concerned. The isitagentready audit jumped from a score of ~20 to 43 overall, with all the things I care about now showing “green” (check it out).
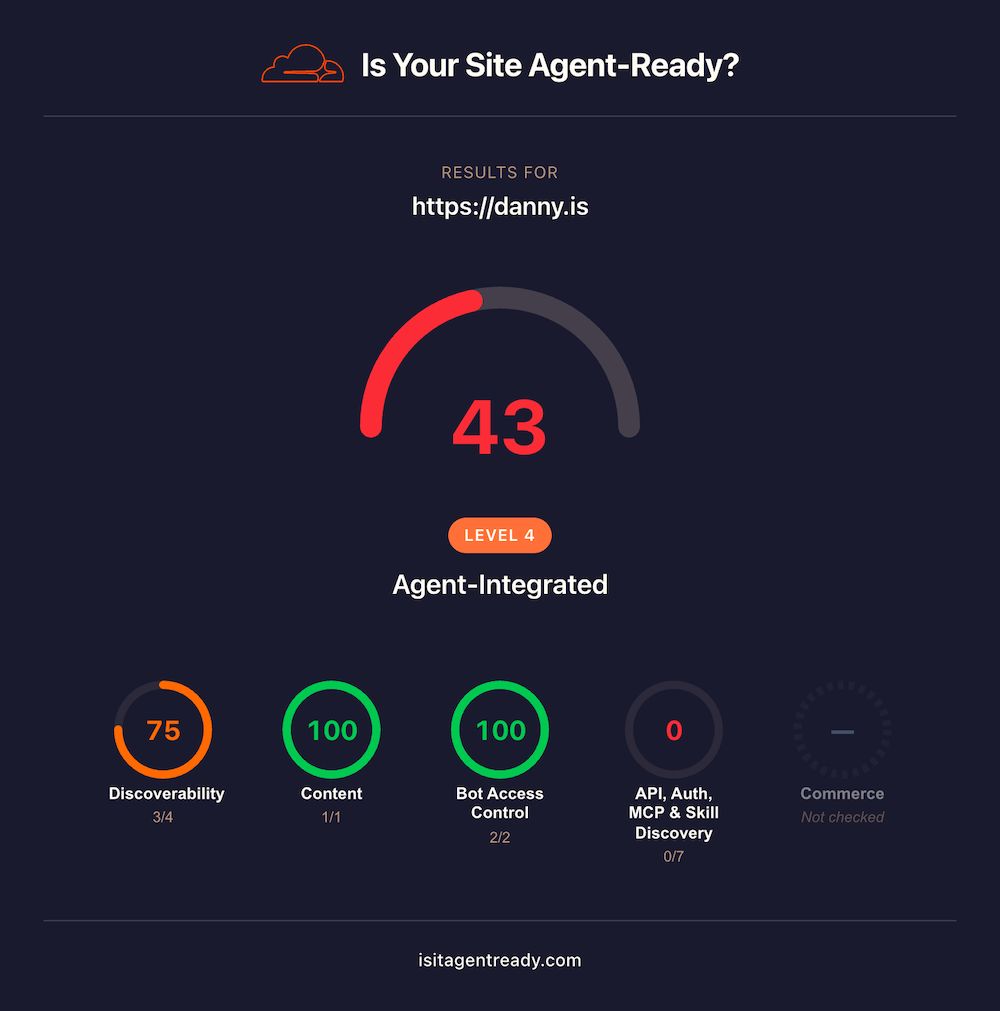
Most of the “failures” here have to do with API, Auth, MCP & Skill Discovery. Not only are these extremely new/immature standards, they’re also not very relevant to content-first websites like this one.
Wrapping up
None of this was difficult to do, but it did require a few minutes actually thinking about how agents consume content on a site like this. I think my biggest takeaway here is that it doesn’t really matter whether /llms.txt is adopted as a standard by harness-makers, in the same way it doesn’t really matter about RSS vs Atom feeds. But it does matter that I – as a website owner – do my best to signpost users appropriately so they know where to find stuff.